
 DC/OS Documentation
DC/OS DocumentationMonitoring the health of all the pieces that make up DC/OS is vital to datacenter operators and for troubleshooting hard-to-diagnose bugs. You can monitor the health of your cluster components from the DC/OS UI component health page. The component health page displays information from the system health API, which monitors the core DC/OS components.
DC/OS components are the systemd units that make up the core of DC/OS. These components are monitored by our internal diagnostics utility (dcos-diagnostics.service). This utility scans all the DC/OS units, and then exposes an HTTP API on each host. For a complete description of the DC/OS components, see the documentation. The component health page provides the health status of all DC/OS system components that are running in systemd. You can drill down by health status, host IP address, or specific systemd unit.
Getting Started
Launch the DC/OS UI and navigate to the System -> Components page. You can sort components by health.
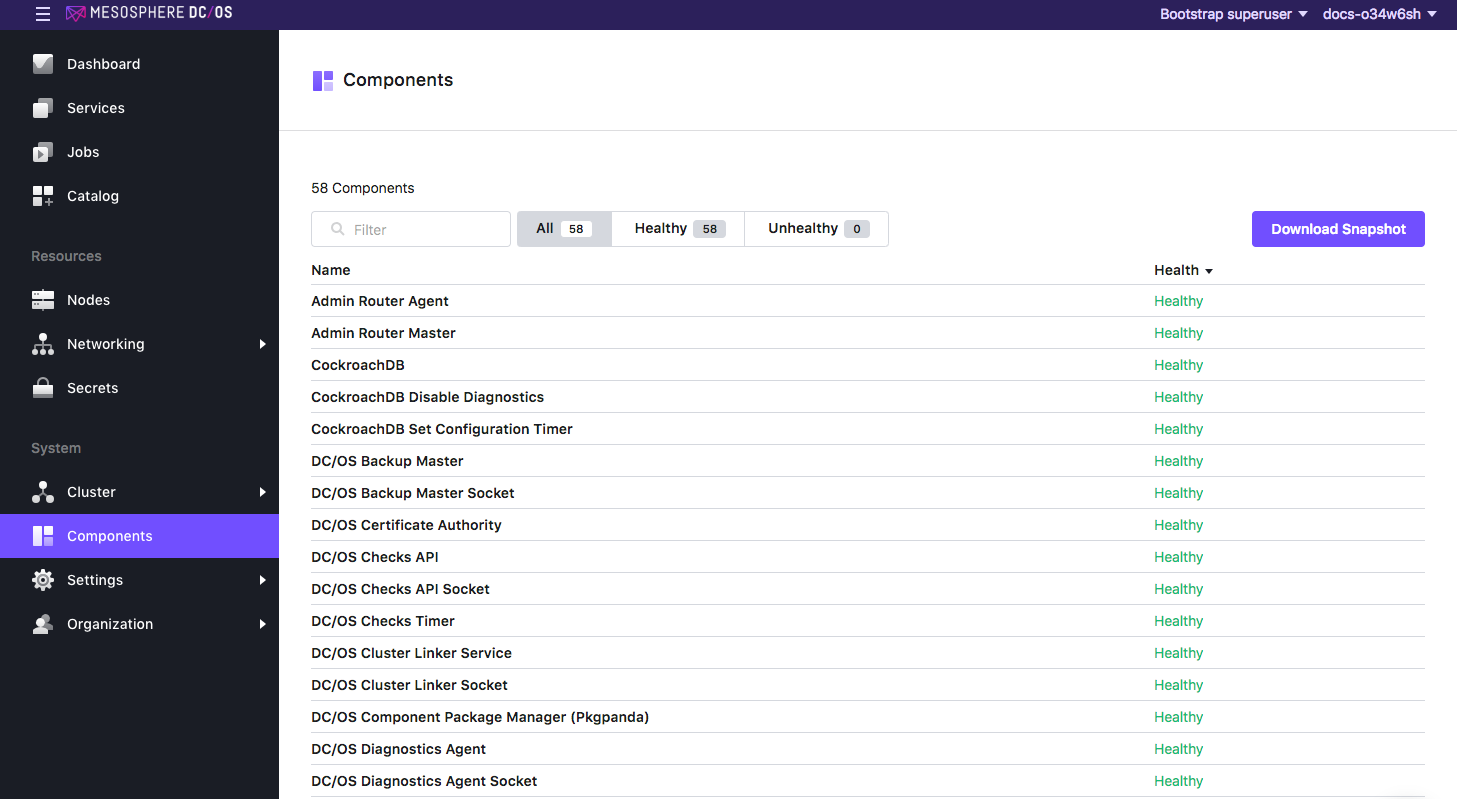
Figure 1. Components page showing health status
You can click on a DC/OS component to view the details, including role, node, and health.
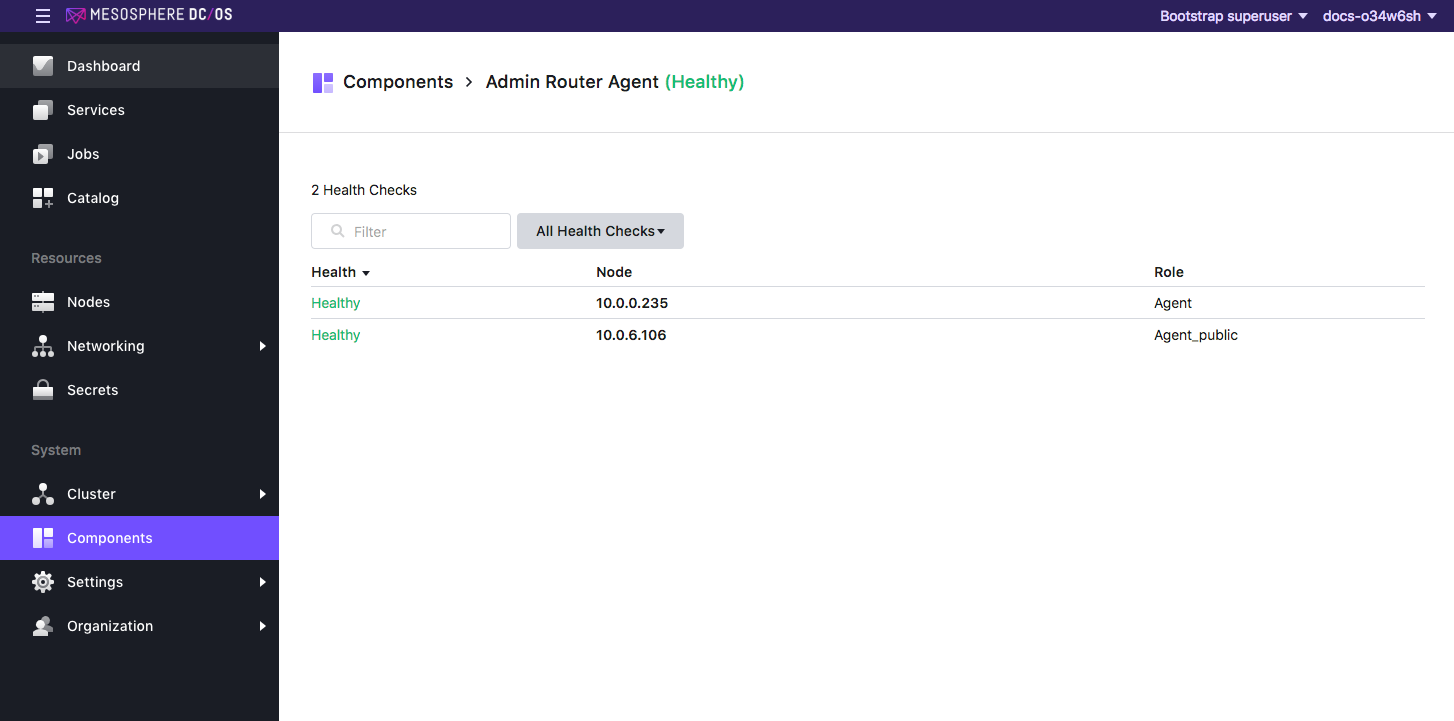
Figure 2. Individual component detail
You can debug further by clicking the node to view the component journald (log) output.
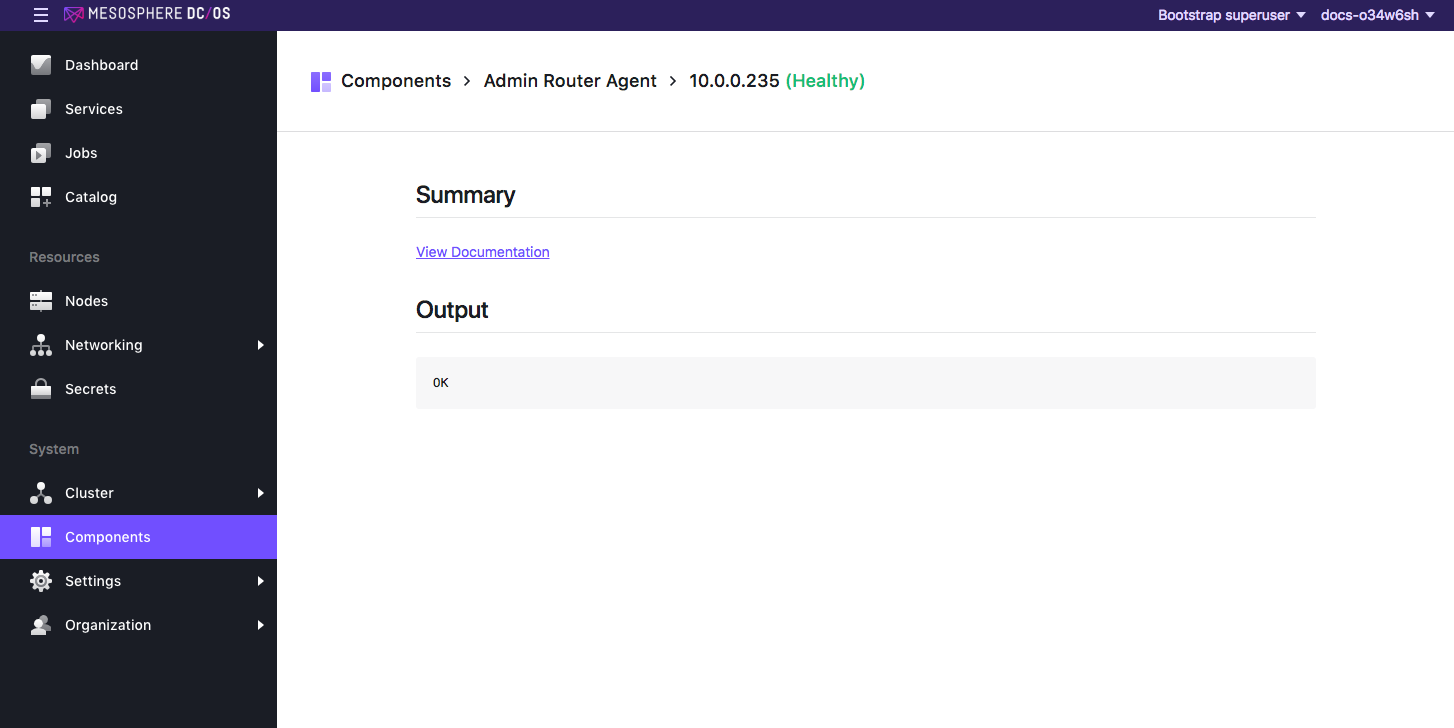
Figure 3. Journald log output
Health States
Possible health states are unhealthy and healthy. We infer this from codes 0 and 1.
- Healthy All cluster nodes are healthy. The units are loaded and not in the “active” or “inactive” state.
- Unhealthy One or more nodes have issues. The units are not loaded or are in the “active” or “inactive” state.
The system health API has four possible states: 0 - 3, OK; CRITICAL; WARNING; UNKNOWN.
System health HTTP API endpoint
The system health endpoint is exposed through the DC/OS diagnostics utility on the master nodes:
curl --unix-socket /run/dcos/dcos-diagnostics.sock http://localhost/system/health/v1
Aggregation
Aggregation of the cluster health endpoints is accomplished by the same diagnostics application on the master nodes. You can explore this API further by making a few queries to any master in your cluster:
-
SSH to your master node:
dcos node ssh --master-proxy --leader -
Run this command to open a root session:
sudo su - -
Run these commands to get cluster health:
-
System health by unit:
curl --unix-socket /run/dcos/dcos-diagnostics.sock http://localhost/system/health/v1/units -
System health by node:
curl --unix-socket /run/dcos/dcos-diagnostics.sock http://localhost/system/health/v1/nodes -
System health report:
curl --unix-socket /run/dcos/dcos-diagnostics.sock http://localhost/system/health/v1/report
-
The DC/OS user interface uses these aggregation endpoints to generate the data you explore in the system health console.
Known Issues
Misinterpreting system health by unit
You can sort system health by systemd unit. However, this search can bring up misleading information, as the service itself can be healthy but the node on which it runs is not. This manifests itself as a service showing “healthy” but nodes associated with that service as “unhealthy”.
Missing cluster hosts
The system health API relies on Mesos-DNS to know about all the cluster hosts. It finds these hosts by combining a query from mesos.master A records as well as leader.mesos:5050/slaves to get the complete list of hosts in the cluster. This system has a known bug, in which an agent will not show up in the list returned from leader.mesos:5050/slaves if the Mesos agent service is not healthy. This means the system health API will not show this host. If you experience this behavior it is most likely that your Mesos agent service on the missing host is unhealthy.
Diagnostics bundle contents
The contents of the generated bundle are not stable over time and any internal or third party bundle analysis tooling should be programmed very defensively in this regard.
Troubleshooting
If you have any problems, you can check if the diagnostics service is running by SSHing to the Mesos leading master and checking the systemd status of the diagnostics component (dcos-diagnostics.service).