DC/OS Documentation
DC/OS DocumentationYou can drain tasks from an agent node in an active DC/OS™ cluster in order to take the node down for maintenance or to remove it permanently from the cluster. Nodes may be drained and their progress may be monitored via the DC/OS CLI or UI.
Initiating draining causes all tasks on the target agent node to receive a kill event immediately, assuming the agent is currently reachable. If the agent is unreachable, initiation of the kill event will be delayed until the agent is reachable by the master again. When the tasks receive a kill event, a SIGTERM signal will be sent to the task to begin the killing process. Depending on the particular task’s behavior, this signal may be sufficient to terminate it. Some tasks may use this signal to begin the process of graceful termination, which may take some time. After some delay, a SIGKILL signal will be sent to the task, which forcefully terminates the task if it is still running. The delay between the SIGTERM and SIGKILL signals is determined by the length of the task’s kill grace period. If no grace period is set for the task, a default value of several seconds will be used depending on configuration.
Prerequisites:
- DC/OS CLI installed and configured.
- Sufficient permissions to drain nodes (DC/OS Enterprise only).
Maximum Grace Period
You can set a max grace period when draining, which sets an upper bound on the duration of the kill grace period. When this is set, the minimum of the task’s grace period and the max grace period will be used when killing the task.
Decommissioning an Agent After Draining
In some cases, such as autoscaled cloud instances which are later scaled down, after the node is drained and taken down, it will never come back again. Each agent node is uniquely identified by metadata on its hard disk, so even if other instances are scaled up in the future, if they don’t retain the persisted metadata of the previous instances, they are viewed as new nodes by the DC/OS cluster.
In cases where the unique agent will not return after it is drained and removed from the cluster, you can specify an option which will automatically decommission the node after it has finished draining, which removes the agent’s metadata from the cluster. If this option is not specified, the cluster will remember the agent node in case it re-registers with the cluster later.
Draining with the CLI
To drain a node with the DC/OS CLI, first locate the Apache® Mesos® agent ID for the node in the ID column of the following command’s output:
dcos node list
Then use that ID with the dcos node drain command:
dcos node drain <mesos-agent-id>
The maximum grace period and/or decommission options may be specified similar to this example:
dcos node drain <mesos-agent-id> --max-grace-period=10m --decommission
After draining on an agent has begun, you can monitor the tasks on that node by running the command:
dcos task list --agent-id=<mesos-agent-id>
You can monitor the overall progress of draining on the node with the following command:
dcos node list --mesos-id=<mesos-agent-id>
Locate the STATUS field: the usual status of a node will be ACTIVE. When draining is initiated on the node, it will change to DRAINING. After all tasks have been killed and their terminal status updates have been acknowledged by the relevant services, and after all resource operations on the node have finished, it will change to DRAINED. When the node is in the DRAINED state, draining is complete.
If the --decommission option was included in the initial drain command, the node’s metadata will be automatically removed from the cluster when draining is complete.
If the decommission option is not specified, the cluster will wait for the node to be reactivated manually after any planned maintenance or other update procedures are finished.
Before performing maintenance, stop the dcos-mesos-slave systemd unit (or dcos-mesos-slave-public for public agents) on the node so that the agent no longer attempts to register with the master:
systemctl stop dcos-mesos-slave
Reactivating an Agent Node After Maintenance
When maintenance is complete and you are ready to reactivate the node and allow it to rejoin the cluster, you may do so with the following command:
dcos node reactivate <mesos-agent-id>
Then start the dcos-mesos-slave systemd unit (or dcos-mesos-slave-public for public agents) by executing the following command on the node, and the agent will rejoin the cluster:
systemctl start dcos-mesos-slave
Monitoring Draining with the UI
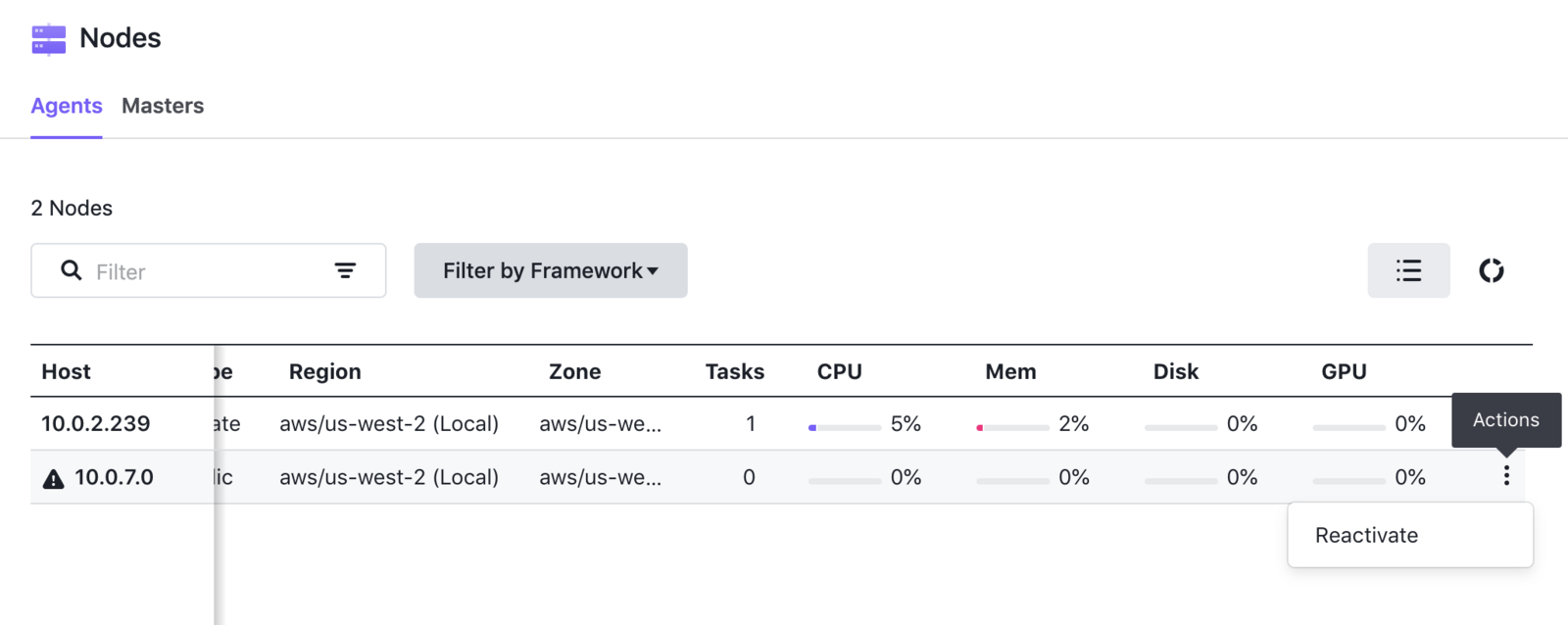
You may also monitor the draining of an agent using the DC/OS UI. To do so, navigate to the Nodes overview pane. The Status column will list either Active, Draining, or Drained, similar to the output of the CLI’s node list command.
Notes Regarding Node Draining
After draining is initiated on an agent node, it cannot be cancelled. This command should be used with caution, especially if executed with the --decommission option, as this results in the node’s permanent removal from the cluster when draining is complete.
If a node becomes stuck in the DRAINING state and does not transition to DRAINED after the expected duration (either the duration specified in the --max-grace-period argument, or the longest kill grace period of the tasks running on the node), then it should be inspected to determine the cause. It is not necessary to issue the dcos node drain command again after a node is in the DRAINING state. Repeating the command will have no effect. If all tasks on the node have terminated, then it’s possible that either a terminal task status update has not been acknowledged by the relevant service, or a resource operation on that node has not finished. To rule out the task status update, inspect the relevant services which were running tasks on the node and ensure that they are running and available. You can list the tasks on the node to discover which services may not have acknowledged their terminal updates:
dcos task list --agent-id=<mesos-agent-id>
If you determine that a particular task or operation is causing the agent to be stuck in the DRAINING state, you should identify the Mesos framework associated with that task and determine what has happened to it. Likely the framework is either gone and not coming back, or it is running on a node which is partitioned from the cluster. If the framework is definitely gone from the cluster but has left unacknowledged updates behind, you can clean it up manually using the TEARDOWN API call of the Mesos master. Look for the framework’s ID in the frameworks field of the Mesos master’s GET_STATE response.
To rule out a resource operation as the cause of the stuck agent, you can use the GET_OPERATIONS call on the agent node to inspect any currently-pending resource operations. If a resource operation is still in the Pending state, the operation may be long-running and take some time to complete, or it may be stuck due to some issue with the storage backend which is actually performing the operation. You should check the storage provider for any issues.
Draining an Agent Node Manually
While the automatic draining procedure described above is likely sufficient for most use cases, it is also possible to drain a node manually when more control over the draining process is required. To do this, first deactivate the node:
dcos node deactivate <mesos-agent-id>
This will stop any new workloads from being launched on that agent. At this point, the APIs exposed by individual services may be used to kill any tasks running on the node. For example, for typical apps and pods launched via the DC/OS UI, the API of the Marathon container orchestrator can be used to terminate the associated tasks. After all tasks on the node have been killed, it can be taken down for maintenance, and then reactivated after maintenance is complete:
dcos node reactivate <mesos-agent-id>
Draining in the DC/OS Console
To drain a node using the DC/OS web-based console:
-
Open a web browser and log in with administrative user name and password.
-
Click Nodes to display information about your agent nodes.
-
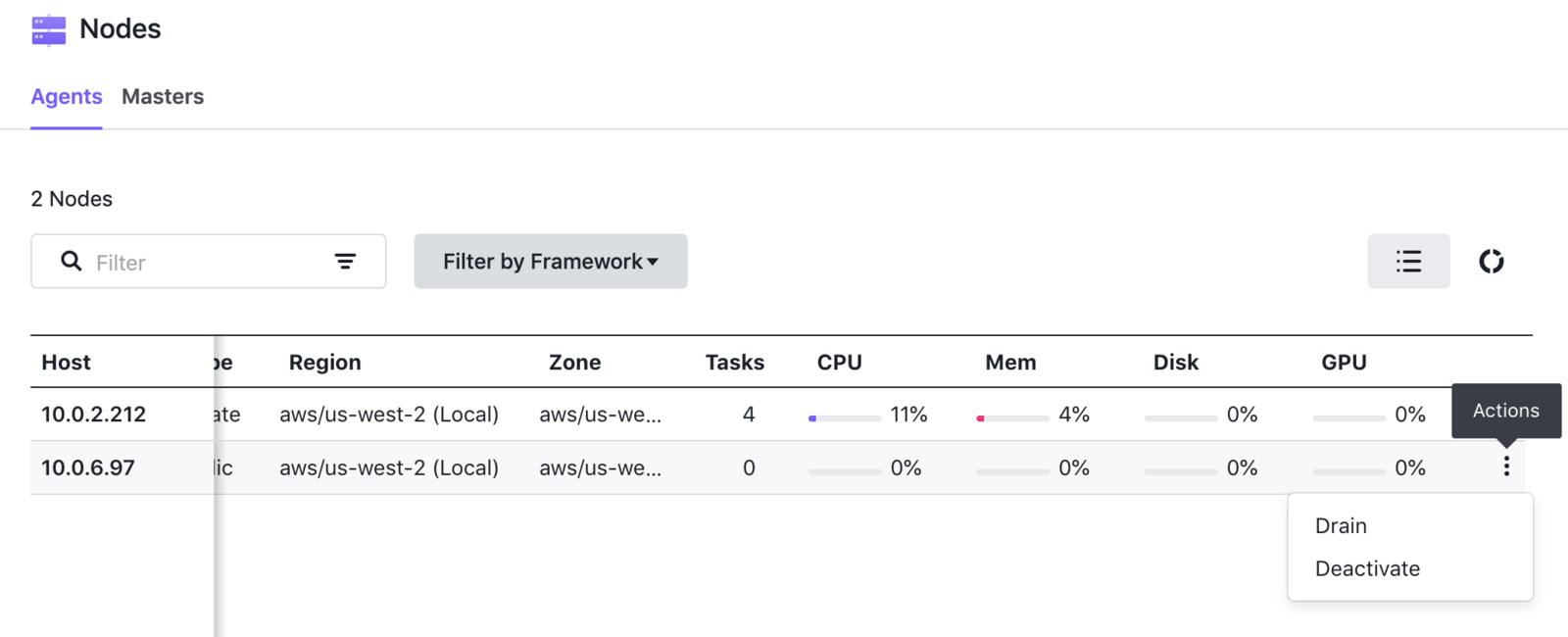
Scroll right to reveal the actions menu for the active node you want to drain.
-
Click Drain and a dialog will appear.
The maximum grace period may be specified in the Drain dialog. This represents the maximum amount of time allowed for tasks to gracefully terminate and overrides a default value of several seconds.
The status column in the Nodes overview will change to reflect the maintenance status of the node.
Decommissioning a Node
When draining a node, you have the option to decommission it after draining is complete.
Deactivating / Reactivating a Node for Manual Draining
Deactivating the node for manual draining is also possible using the actions menu. When maintenance is complete and you are ready to reactivate the node and allow it to rejoin the cluster, click the Reactivate action from the menu: