
 DC/OS Documentation
DC/OS DocumentationMetrics in DC/OS 1.12 and newer versions are based on Telegraf. Telegraf metrics are the internal representation used to model data during processing. Telegraf provides an agent-based service that runs on each master and agent node in a DC/OS cluster. By default, Telegraf gathers metrics from all of the processes running on the same node, processes them, then sends the collected information to a central metrics database. Telegraf has a plugin-driven architecture. The plugin architecture enables Telegraf to collect information from a supported input plugin and write results to a supported output plugin. The plugins are compiled into the Telegraf binary for execution, and you can selectively enable and customize plugins using configuration file options. A single instance of Telegraf is seen in Figure 1.
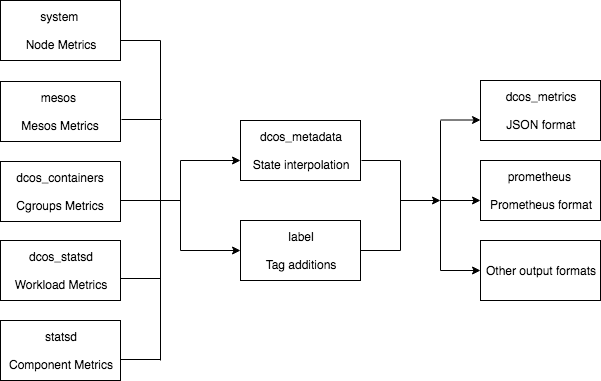
Figure 1. A single instance of Telegraf
By default, DC/OS enables the following Telegraf plugins:
systeminput plugin collects information about the node, for example, CPU, memory, and disk usage.statsdinput plugin collectsstatsdmetrics from DC/OS components.prometheusinput plugin collects metrics from DC/OS components andmesostasks.mesosinput plugin collects metrics about themesosprocess itself.dcos_statsdinput plugin starts a newstatsdserver for eachmesostask.dcos_containerscollects resource information about containers from themesosprocess.overrideplugin is used to add node-level metadata, for example, the cluster name.dcos_metadataplugin is used to add task-level metadata, for example, the executor name and task name.dcos_metricsoutput plugin serves thedcos-metricsJSON API, which is used by the CLI.prometheus_clientoutput plugin serves metrics in Prometheus format.
When Telegraf starts on a node, it loads a configuration file and the contents of a configuration directory or directories. You can specify the plugins you want to enable by creating a configuration file with the appropriate settings and copying the file into the /var/lib/dcos/telegraf/telegraf.d directory before restarting Telegraf. Only files ending with .conf will be included in the Telegraf configuration. Note: Any mistakes in the configuration files will prevent Telegraf from starting up successfully.
Telegraf abstracts the complexity of collecting metrics from every process running in the cluster by providing a single source for metrics on each node. Telegraf also adds identifying metadata–such as the originating task name–to the metrics it collects to make the metric more human-readable. Without this metadata, metrics for tasks running on Mesos would be difficult to identify by their originating container ID, which is a long random hash.
The DC/OS fork of Telegraf includes technical documentation and sample configurations for each plugin.